12月2日,南京农业大学信息管理学院王东波教授研究团队在北京发布“荀子”古籍大语言模型。“荀子”古籍大语言模型是该团队在国家社科基金重大项目“中国古代典籍跨语言知识库构建及应用研究”的支持下,联合中华书局古联公司推出的专门进行古籍处理与研究的智能工具。该模型包含《四库全书》在内的绝大多数传世古籍文献,拥有超过20亿字的大型语料库。
“荀子”古籍大语言模型以古籍智能化研究为目的,为古籍智能处理而设计,在推动我国古籍研究与保护工作创新发展、提高中华传统文化传承的效率与质量、实现大语言模型与古籍处理的深度融合上提供重要支撑。该模型作为开源公益研究成果已在GitHub、ModelScope等网站发布,用户可免费下载部署使用。
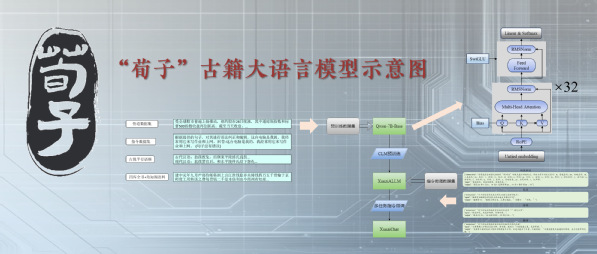
据介绍,王东波教授研究团队在南京农业大学高算力基础设施支持下,持续10年深耕古籍文献数字化研究,同时依托中华书局提供的应用场景,在古籍开源大语言模型上实现AI人工智能垂直细分领域的全国首创。该开源模型包括基座模型XunziALLM与对话模型XunziChat两个部分。其模型亮点包括:智能标引,能够对古籍中的内容进行高质量主题标引,帮助研究人员快速了解文章主题;信息抽取,能够自动从古籍中抽取关键信息,如人物、事件、地点等,大大节省了信息整理时间;诗歌生成,能够根据给定的主题或关键词,自动生成符合语法规则和韵律要求的古诗,为诗词爱好者提供创作灵感;高质量翻译,对于难以理解的古籍文献,能够进行精准的现代文翻译,帮助研究人员更好地理解原文含义;阅读理解,能够对给出的古文文本进行分析解释,实现对古籍文本的自动阅读;词法分析,可以完成古籍文本的自动分词和词性标注,有效提升研究效率;自动标点,可以快速完成古籍文本的断句和标点,提升使用者对古籍文本的阅读体验。此外,同时发布的基座模型,用户也可以根据自己的需求,使用本地的训练语料微调“荀子”基座模型,使其在古籍下游处理任务上取得更优越的处理性能。
发布会现场,研究团队进行了包括词法分析、实体识别、关系抽取、文本分类与匹配、文本翻译等古籍处理场景的模型演示。国内高校、出版界和互联网头部企业的众多专家学者参加了发布会,与会者亲身体验了模型的实用性和直观效果,并给予了高度评价。
模型链接 https://github.com/Xunzi-LLM-of-Chinese-classics/XunziALLM